腾讯开源 TencentDB Agent Memory:给 OpenClaw 和 Hermes Agent 接上 4 层本地长期记忆
摘要
腾讯 4 月初放出 TencentDB Agent Memory,7 周攒下 4.1K stars。它的思路有点反潮流 - 不再把对话历史塞进扁平向量库,而是建一座 L0 Conversation → L1 Atom → L2 Scenario → L3 Persona 的语义金字塔;短期任务状态再用 Mermaid 符号图替代工具日志。已经支持 OpenClaw 插件和 Hermes Agent 镜像,在 PersonaMem 上把准确率从 48% 拉到 76%,WideSearch 上 token 消耗砍掉 61%。这篇拆开看它的两根支柱、两条集成路径,和几段值得抄走的工程实现。
每个用 agent 久一点的人都会有一个共同的疲劳点 - 同一个项目背景,同一套 SOP,同一种输出格式,你跟它解释了一百遍,它还是每次重开都问你「你想要什么风格」「这个项目的技术栈是什么」。
把历史扔进上下文,token 爆掉;把历史扔进向量库,召回出一堆相关但不连续的片段。两个方向都不解决「让 agent 自己记住什么该问、什么不该问」这件事。
腾讯 4 月初开源的 Tencent/TencentDB-Agent-Memory(以下简称 TDAI)就在试着回答这个问题。7 周拿到 4.1K stars,5 月 23 日被 MarkTechPost 写了一篇深度介绍,5 月 25 日还在持续提交。和大多数 agent memory 方案比,它最不一样的一点是 - 拒绝扁平向量存储。
一个反传统的姿态:记忆不是向量堆,是金字塔
TDAI 的 README 一开头就把这条立场摆出来:
Traditional memory systems shred data into fragments and dump them into a flat vector store. Recall degenerates into a blind search across disconnected fragments, with no macro-level guidance.
翻译过来 - 传统记忆方案把数据剁成碎片扔进扁平向量库,召回变成在断片之间瞎找,没有宏观指引。
它的替代方案有两根支柱:
- 记忆分层(Memory Layering) - 长期记忆做成自下而上的语义金字塔,下层保留证据,上层保留结构
- 符号化记忆(Symbolic Memory) - 短期任务状态压成 Mermaid 图,工具日志原文卸载到外部文件
下层证据 + 上层结构这套思路本身不新,但 TDAI 把它彻底落到代码里,并且坚持「白盒可调试」- 每一层的中间产物都是人类可读的 Markdown 或 JSONL,不是黑箱向量。
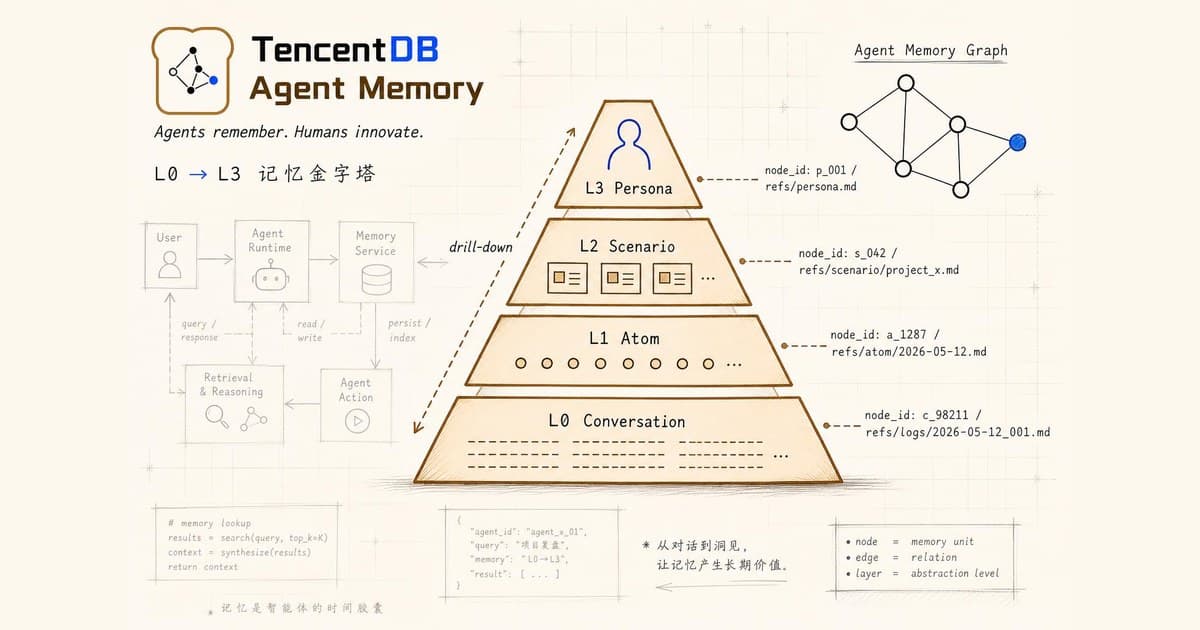
长期记忆的 4 层金字塔:L0 → L3
这是 TDAI 最容易被抄走、也最值得理解的设计。一条对话进来之后,它会逐层往上蒸馏:
| 层级 | 内容 | 存储形态 | 作用 |
|---|---|---|---|
| L0 Conversation | 原始对话日志 | SQLite + JSONL | 证据层 - 任何上层推断都能回溯 |
| L1 Atom | 原子事实(atomic facts) | JSONL,可去重 | 索引层 - 单点事实可用关键词/向量检索 |
| L2 Scenario | 场景块(scene blocks) | Markdown 文件 | 主题聚合层 - 把 atom 按上下文场景归簇 |
| L3 Persona | 用户画像 | persona.md | 偏好层 - 跨 session 的长期判断依据 |
实际生效路径是反向的 - 答问题先看上层,缺细节再向下钻:
| 问题类型 | 首查 | 必要时下钻到 |
|---|---|---|
| 日常偏好、语气、长期目标 | L3 Persona / L2 Scenario | L1 Atom / L0 Conversation |
| 具体事实、日期、项目细节 | L1 Atom / L0 Conversation | 放宽时间窗口,或退回向量召回 |
| 长任务续写 | 顶层 Mermaid task canvas | JSONL summary → refs/*.md 原文 |
| 历史任务复盘 | 元数据任务入口 | Mermaid canvas → node_id → result_ref |
整条钻取链 README 里有一个清晰的说法 - 「顶层符号(Persona / canvas)→ 中层索引(Scenario / jsonl)→ 底层原文(L0 Conversation / refs)」。这意味着:当你看到一句 "用户偏好写 Python 而不是 Go",你能顺着 persona → 触发这条结论的几个 scenario → scenario 里抽出的 atom → atom 引用的原始对话,一层层验证。
对比之下,单纯的向量库召回出 3 条相关 chunk,然后让 LLM "summarize",错了你不知道错在哪 - 这是 TDAI 强调白盒的原因。
Pipeline 的触发节奏在 openclaw.plugin.json 里:
{
"pipeline": {
"everyNConversations": 5, // 每 5 轮对话触发 L1 提取
"enableWarmup": true, // 新 session: 1 轮 → 2 → 4 → ... → N
"l1IdleTimeoutSeconds": 600, // 用户停 10 分钟也触发 L1
"l2MinIntervalSeconds": 900 // 同 session 两次 L2 至少间隔 15 分钟
},
"persona": {
"triggerEveryN": 50 // 累计 50 条新记忆生成一次 persona
}
}
Warmup 这个细节挺贴心 - 新会话头几轮就触发提取,不用等攒够 5 条;之后翻倍退避到稳态。
短期记忆:Mermaid 图把 50 万 token 压成几百 token
长期记忆解决「跨 session 记得用户」,短期记忆解决「同一个长任务里别被工具日志撑爆 context」。
TDAI 给出的方案是把工具调用记录拆三层处理:
graph LR
Log["Verbose Logs<br/>(数十万 token)"] -->|"1. 卸载全文"| FS[("外部 FS<br/>(refs/*.md)")]
Log -->|"2. 抽取关系"| MMD["Mermaid Canvas<br/>(带 node_id)"]
MMD -->|"3. 轻量注入"| Agent(("Agent 上下文<br/>(几百 token)"))
Agent -. "4. 通过 node_id 回查" .-> FS
- 工具原始输出全量落盘(
refs/*.md)- agent 看不到 - 中间提取出每一步的关系,编码成 Mermaid 节点图 - 每个节点带
node_id - 只有 Mermaid canvas 注入到 context - LLM 既能解析、人也能读
- 哪个节点要看细节,grep
node_id把对应的原始文本拉回来
为什么是 Mermaid 而不是 JSON?官方说法是 - LLM 解析够准、人类读够省力,token 密度比 prose 和 flat JSON 都高。这点我们 0523 的 AI 早读里也提过 Claude Code 的 Thariq Shihipar 在做类似的事(用 HTML 而不是 Markdown 当输出格式)- 都是同一个方向:给 LLM 用的中间表示,要比给人用的更紧凑。
短期压缩的触发阈值:
{
"offload": {
"enabled": true,
"mildOffloadRatio": 0.5, // 上下文用到 50% 开始温和压缩
"aggressiveCompressRatio": 0.85, // 用到 85% 进入激进模式
"mmdMaxTokenRatio": 0.2 // Mermaid canvas 最多占 20% 预算
}
}
OpenClaw 集成:两行命令,零配置
OpenClaw 是 TDAI 的一等公民集成路径。安装就两行:
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
openclaw gateway restart
启用更简单:
// ~/.openclaw/openclaw.json
{
"memory-tencentdb": {
"enabled": true
}
}
之后所有事都是 TDAI 自己做 - 对话捕获、L1 提取、L2 场景聚合、L3 画像生成、下一轮对话开始前的召回注入。默认后端是 SQLite + sqlite-vec,数据落在 ~/.openclaw/memory-tdai/,可以直接打开看每一层长什么样。
要开启短期 Mermaid 压缩多加一行 offload.enabled: true,再跑一次 openclaw-after-tool-call-messages.patch.sh 把 OpenClaw 的 after-tool-call hook 接上即可。
Hermes Agent 集成:Docker 一键起,Python 包 Node.js
第二条集成路径走的是 NousResearch 的 Hermes Agent。这条路径架构上更有意思 - TDAI 核心是 Node.js 写的,但 Hermes 是 Python 框架。怎么接?官方的答案是 Python 进程里跑一个 Node.js sidecar:
flowchart TB
subgraph Hermes["Hermes Agent (Python)"]
MM["MemoryManager"]
MP["MemoryTencentdbProvider"]
GS["GatewaySupervisor<br/>启动 + 健康检查 sidecar"]
SDK["MemoryTencentdbSdkClient<br/>POST /recall · /capture · /search/*"]
MM --> MP
MP --> GS
MP --> SDK
end
subgraph Gateway["TDAI Gateway (Node.js)"]
Core["TDAI Core"]
L0["L0 Conversation store<br/>SQLite / TCVDB + JSONL"]
L1["L1 Episodic extraction<br/>LLM + 向量去重"]
L2["L2 Scene blocks<br/>Markdown"]
L3["L3 Persona synthesis<br/>persona.md"]
Backend["后端: SQLite + sqlite-vec<br/>或 腾讯云向量数据库"]
Core --> L0
Core --> L1
Core --> L2
Core --> L3
L0 --> Backend
L1 --> Backend
end
SDK -. "HTTP 127.0.0.1:8420" .-> Core
style Hermes fill:#FBF0DE,stroke:#8B6332
style Gateway fill:#EFF6FF,stroke:#1A6FD9
Hermes 的生命周期 hook 映射到 Gateway endpoint:
| Hermes hook | Gateway endpoint | 行为 |
|---|---|---|
prefetch(query) | POST /recall | 同步。返回 <memory-context> 文本注入 |
sync_turn(user, assistant) | POST /capture | 后台守护线程触发即忘,最多 4 个 in-flight |
shutdown() / on_session_end | POST /session/end | 刷新 pipeline 残余 |
get_tool_schemas() | - | 暴露 tdai_memory_search 和 tdai_conversation_search 两个工具 |
Python provider 那一层做了几件值得抄的可靠性工程:
- 熔断器 - 连续 5 次 Gateway 失败 → 暂停所有调用 60 秒
- capture 背压 - 最多 4 个并发
sync_turn线程;第 5 个等最老的最多 5 秒再起,防止 sidecar 卡死时线程无限堆积 - 进程监督 - 起 sidecar 后轮询
/health30 秒;崩了自动 tailgateway.stderr.log给 diagnostics - 零配置自动发现 - 在
~/.memory-tencentdb/、~/.hermes/plugins/几个标准路径自动找server.ts
落到使用上,一条 docker run 起整套:
docker run -d \
--name hermes-memory \
--restart unless-stopped \
-p 8420:8420 \
-e MODEL_API_KEY="your-api-key" \
-e MODEL_BASE_URL="https://api.lkeap.cloud.tencent.com/v1" \
-e MODEL_NAME="deepseek-v3.2" \
-e MODEL_PROVIDER="custom" \
-v hermes_data:/opt/data \
hermes-memory
默认模型是腾讯云 LKE 跑的 DeepSeek-V3.2 - 近日 The Decoder 报道 DeepSeek 把 75% 折扣永久化、输出 token 比 GPT-5.5 便宜至少 34 倍。便宜模型 + 本地记忆,这套组合的运行成本可以压得很低。
检索引擎:BM25 + 向量 + RRF 三个一起上
agent 调 tdai_memory_search 的时候,TDAI 同时跑两条召回路径,然后用 RRF 融合:
// src/core/tools/memory-search.ts
const RRF_K = 60; // 经典 RRF 论文的常数
function rrfMergeL1(...lists: MemorySearchResultItem[][]) {
const map = new Map<string, { item: MemorySearchResultItem; rrfScore: number }>();
for (const list of lists) {
for (let rank = 0; rank < list.length; rank++) {
const item = list[rank];
const score = 1 / (RRF_K + rank + 1);
const existing = map.get(item.id);
if (existing) existing.rrfScore += score;
else map.set(item.id, { item, rrfScore: score });
}
}
return [...map.values()]
.sort((a, b) => b.rrfScore - a.rrfScore)
.map(({ item, rrfScore }) => ({ ...item, score: rrfScore }));
}
代码很短,三件事值得注意:
RRF_K = 60是 RRF 原论文(Cormack et al., 2009)的标准常数,不是拍脑袋- 关键词检索走的是 SQLite FTS5(
buildFtsQuery),向量走 sqlite-vec - 完全本地,零外部 API 依赖 - 自动降级 - 没配 embedding service 时直接退回纯 FTS5;没 FTS5 退回纯向量;两个都没就空召回
BM25 那边支持 zh(jieba)和 en 两种分词,中英文场景都能用。
Benchmark:长会话场景下的真实增益
README 给的数字看起来很漂亮,但有个关键约束需要先说清楚 - 这些是连续长会话的成绩,不是单轮对话。比如 SWE-bench 每个 session 跑 50 个连续任务,模拟真实长任务下 context 累积压力。
| 能力 | Benchmark | OpenClaw 裸跑 | 加 TDAI 插件 | 相对增益 | Token 用量变化 |
|---|---|---|---|---|---|
| 短期 | WideSearch | 33% | 50% | +51.52% | −61.38% |
| 短期 | SWE-bench | 58.4% | 64.2% | +9.93% | −33.09% |
| 短期 | AA-LCR | 44.0% | 47.5% | +7.95% | −30.98% |
| 长期 | PersonaMem | 48% | 76% | +59% | - |
PersonaMem 上 48% → 76% 这个跳跃最值得关注 - 因为它直接测的就是 "agent 是否记得你"。WideSearch 的 token 砍 61% 也很硬 - 短期记忆这套 Mermaid 卸载方案在搜索类长任务上对成本影响最大。
SWE-bench 上 +9.93% 看起来小,但考虑到这是个高度工程化的代码 benchmark,能在 50 任务的连续 session 里把 pass rate 又往上推 6 个百分点(同时 token 砍掉 1/3),增量并不小。
几个 tradeoff 和适用场景
- 短会话用不上 - 几轮就结束的 chat,pipeline 都没触发完,分层没意义
- 冷启动需要时间 - 新用户没 persona,需要积累 50 条 L1 atom 才能出第一版 persona;warmup 缓解了这点但不能消除
- 依赖一个 LLM 做提取 - L1 / L2 / L3 都靠 LLM 蒸馏,本地存储但 LLM 调用仍要计入成本(默认走 OpenClaw 的模型,或单独配
llm.*) - 目前只对接两个宿主 - OpenClaw 和 Hermes。LangChain / LangGraph / AutoGen / Claude Code 没有官方插件,要自己写 host adapter(
TdaiCore + HostAdapter解耦设计,理论上能接) - 和 mem0 / Letta 不完全重叠 - mem0(56K stars,Apache 2.0)和 Letta(23K stars,Apache 2.0)也都是开源的 agent memory 项目,但它们设计上偏 SDK / 框架,托管层(mem0 Cloud / Letta Cloud)是主要变现路径;TDAI 默认本地优先,没有官方托管服务,定位更接近「OpenClaw 生态里的开箱即用插件」
适用场景比较明确:
- 你有一个长期、多 session 跟同一个用户打交道的 agent(编程助手、研究伴侣、知识 worker)
- 你不想把对话历史交给第三方 SaaS - 本地 SQLite 起步够用
- 你接受用 OpenClaw 或 Hermes 当 host,或者愿意自己写 adapter
怎么开始
最低成本的路径是装 OpenClaw + 这个插件 - 两行命令 + 一段配置,跑起来之后打开 ~/.openclaw/memory-tdai/ 看每一层产出。三天之后再回头看 persona.md 里它给你画出了什么 - 这是最直接的体感测试。
判据很简单:
- 你不需要在新会话里重新解释项目背景了
- agent 主动援引你三周前说过的偏好
- 长任务里它没被工具日志撑爆 context
这三件事变成常态,TDAI 就在干活儿了。
往大了说,agent memory 还远没收敛 - mem0、Letta、Zep、Hippo、Claude Code 的 CLAUDE.md,每一家在解决同一个问题的不同切面。TDAI 的贡献在于 - 它把「分层 + 符号化 + 白盒可调试」这三件事一起做了,并且把代码全开源出来,让你能看到每一层的产物。这种透明度本身就是稀缺品。
4129 stars 不是终点,但确实说明社区在等一个本地优先、能 debug、能审计的 agent memory 方案。
- 仓库:Tencent/TencentDB-Agent-Memory
- npm 包:@tencentdb-agent-memory/memory-tencentdb
- OpenClaw 集成:openclaw.plugin.json
- Hermes 集成:
hermes-plugin/memory/memory_tencentdb/
相关文章
2026年5月7日
Cloudflare 一周拆了 Agent 的两堵墙:Code Mode MCP 与 Agent Memory
Code Mode MCP 把 1.17M tokens 的 API 压成 1K,Agent Memory 把对话历史压成可索引的结构化记忆。两个公告分开看是产品发布,放一起看是同一个判断 - agent 跑不动了,得重新设计存储层。
2026年3月12日
OpenClaw 龙虾市集:大厂排队取餐,创始人买单
百度在公司楼下办了个龙虾市集帮人装 OpenClaw,腾讯爬光了 ClawHub 做了个 SkillHub。创始人 steipete 说:你们吃得很开心,账单能看一眼吗?
2026年2月24日
一条命令跑起来:用 Ollama 运行 OpenClaw 个人 AI 助手
Ollama 0.17 新增 launch 命令,一行搞定 OpenClaw 的安装、配置和启动。开放模型跑个人 AI 助手从没这么简单过。
最近一封 · Sample
【AI早读 0709】智能体评估困局与工程化新思路
“OpenAI 发表 audit 报告《Separating signal from noise in coding evaluations》,把业界常用的编程评测集 SWE-Bench Pro 翻箱倒柜查了一遍,结论有点尴尬 - 大约 30% 的题目是坏的。围绕智能体评估,harness 工程化成了新的关注点。”
—— william
来信
里面装的是
- 新文章 — 写完一篇就寄一封,不攒货
- 这周读到的、看到的、好用的工具
- 正在折腾的实验,附带翻车记录
约莫 1–2 周一封 · 随时退订
合作伙伴
CompeteMap — 英国及爱尔兰学生竞赛一站式搜索
数学、编程、科学、写作等各类竞赛信息汇总,支持按年龄和科目筛选,再也不错过报名截止日。