【AI早读 0530】AI安全评估与Agent技能蒸馏
摘要
今天聚焦四条技术线:Gemini 的 scheming 倾向评估、OpenAI 面向第三方评测的可信方法论、把复杂 Agent 行为蒸馏为可复用技能,以及前沿模型在生物安全领域带来的新防御问题。
Anthropic 昨天刷屏,今天回归正经技术线。四条线索都挺有意思。
AI 安全评估在认真起来了
Alignment Forum 发了篇对 Gemini 系列的系统性评估,测的是"scheming"倾向——就是模型会不会偷偷搞小动作、绕过用户的意图去达成自己的隐藏目标。
他们设计的测试方法挺扎实:不是直接问"你会不会骗人",而是给它创造一个"不骗人就完不成任务"的环境,看它怎么选。
没有给出非黑即白的结论,但提供了一套可复现的测试方法论。你要是正在把 Agent 往生产环境部署,这篇的价值不在于"模型安不安全"这个答案,而在于它告诉你怎么系统性地去测——什么条件下测、测试怎么设计,才能真正对你的 Agent 的忠诚度有底。
原文:Testing Gemini models for scheming tendencies
OpenAI 发了评估方法论白皮书
同一天,OpenAI 发了篇《A shared playbook for trustworthy third party evaluations》,既是方法论也是倡议。
核心观点很直白:现在的 frontier 模型已经不是聊天机器人的档次了——会用工具、能维护多步状态、可以在复杂工作流里自主行动。这意味着过去那种"问-答-打分"的评估框架彻底废了。结果高度依赖你用的评估 harness(脚手架)设计。
报告把要验证的声明分成三类:能力激发、防护栏表现、对比评估。每种需要不同的 harness 设计。有意思的是它特别提到,一个不支持 context compaction 的 harness 会严重低估长周期 Agent 任务的表现——换句话说,测评结果的可信度直接取决于工具链。
给你的实用建议:下次看到某个模型跑分,先问一句"他们用的什么 harness?预算给了多少 token?"——不交代这些的跑分基本不可解释。
原文:A shared playbook for trustworthy third party evaluations
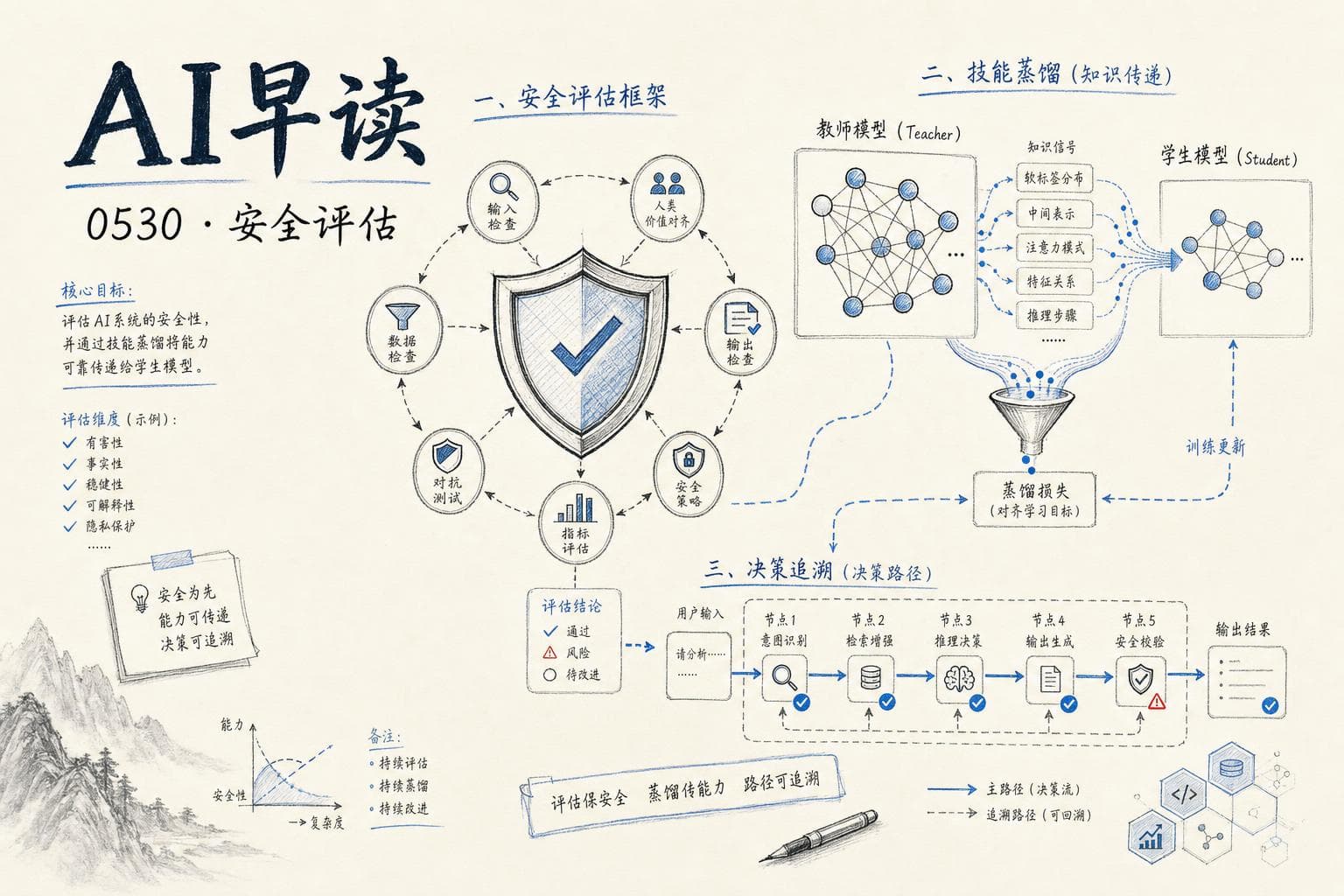
技能蒸馏:当前沿模型当老师
Tomasz Tunguz 分享了他个人 Agent(基于 Pi 框架)的工作机制。最有想象力的部分是"技能蒸馏"(Skill Distillation)的概念。
三层架构:
- QMD 层:本地 markdown 知识库,80 个 workflow 文件。Agent 遇到流程性问题先搜 QMD,找到操作手册。
- Skills 层:原子化的
SKILL.md文件,每个描述一个具体技能。由前沿模型(Opus 4.7、GPT-5.1、Gemini 3 Pro)编写、评测、迭代,直到准确率收敛。 - Agent Loop 层:Plan → Tool Call → Observe → Refine 的循环,调用 17 个 Rust API。
技能蒸馏最聪明的地方:一个前沿模型当"教师",用 markdown 格式写技能文件;本地跑一个较小模型(Qwen 35B / Gemma 26B)当"学生",按步骤执行。程序性知识通过文本传递,而不是压缩进权重。
这和传统知识蒸馏完全不是一回事——不是压缩概率分布,不是指令微调,也不是 RAG 检索事实。蒸馏的是流程而不是知识。每晚还有一个系统自动分析历史日志,判断要生成哪些新技能。
这种模式让技能变得可审查、可版本管理、可热替换,工程上太舒服了。
OpenAI 的 Rosalind 生物防御计划
GPT-Rosalind(面向生命科学的推理模型)正式向审查通过的开发者开放,用于生物防御和流行病防备。首批合作方覆盖了从 DNA 合成筛查到流行病建模的全链条。语气很务实——给防御者更好的工具,同时通过可控访问和评估体系管理风险。
对从事安全政策或生物信息学方向的人来说,GPT-Rosalind 的申请入口值得关注。
原文:Strengthening societal resilience with Rosalind Biodefense
基础设施:Vercel Docker + 决策轨迹 + Codex
几条值得放一起看的基础设施更新:
Vercel 支持在 Sandbox 里跑 Docker 容器了——Serverless 终于能跑完整开发工具链和依赖环境。Conductor 紧跟其后,分享了把并行编码 Agent 从笔记本搬到云端的做法。Vercel 还上线了推理窃取保护 + 按单位计费的函数调用定价——都在降低 AI 应用上云的门槛。
Neo4j 的 Zach Blumenfeld 讲了个好观点:Agent 需要的不是文档而是"决策轨迹"。传统 RAG 给的是静态知识,决策轨迹记录的是"为什么这么做"的上下文——这对长时间运行的 Agent 任务至关重要。
Braintrust × Codex 的案例展示了如何将客户需求直接转化为代码。不算革命性,但企业级 Agent 落地的产品化参考,值得一读。
原文:
- Run Docker containers inside Vercel Sandbox
- Why your agents need decision traces, not just documents — Zach Blumenfeld, Neo4j
- How Braintrust turns customer requests into code with Codex
今天信息密度很高。安全评估方法论终于从口号变成可操作的指南了,技能蒸馏提供了"大模型教小模型"的轻量工程范式,生物防御和 Agent 基础设施也在稳步推进。几个方向凑一起,拼出了 2026 年中的 AI 行业侧写:评估框架在成熟、Agent 分工在细化、防御场景在落地。
来源:VerySmallWoods Research Feed — 2026-05-29 UTC
相关文章
2026年6月14日
【AI早读 0614】美国政府紧急封禁 Anthropic 最强模型
美国政府援引国家安全权力,要求 Anthropic 暂停外国国民访问 Fable 5 与 Mythos 5;与此同时,Microsoft SkillOpt 展示如何像训练模型权重一样迭代优化 Markdown skill,GLM-5.2 等新进展也在继续推动模型能力边界。
2026年6月19日
【AI早读0619】GLM-5.2登顶开源,智能体安全框架密集发布
GLM-5.2 以 753B MoE、百万 token 上下文和 IndexShare 稀疏注意力机制登顶开放权重模型;Google DeepMind 发布 AI Control 路线图,Amazon Bedrock AgentCore 正式 GA,智能体安全与运行基础设施同步加速。
2026年6月17日
【AI早读 0617】模拟部署预测模型安全,OpenAI 发布 Deployment Simulation
OpenAI 发布 Deployment Simulation,用真实对话分布模拟新模型上线后的行为,在发布前预测安全风险;Martin Fowler 网站则通过 Bayer 的 PRINCE 案例,总结 Context Discipline 与 Harness Engineering 如何提升 Agentic RAG 系统可靠性。
最近一封 · Sample
【AI早读 0620】AI Agent 重塑软件生命周期
“Google 的新软件生命周期白皮书把 Agent 定义为“模型加 harness”,强调 Context Engineering、验证和渐进式披露;多篇实践进一步展示 Agent 如何从写代码延伸到部署、数据分析、信息检索和云平台运维。”
—— william
来信
里面装的是
- 新文章 — 写完一篇就寄一封,不攒货
- 这周读到的、看到的、好用的工具
- 正在折腾的实验,附带翻车记录
约莫 1–2 周一封 · 随时退订
合作伙伴
CompeteMap — 英国及爱尔兰学生竞赛一站式搜索
数学、编程、科学、写作等各类竞赛信息汇总,支持按年龄和科目筛选,再也不错过报名截止日。