【AI早读 0531】Anthropic 把 Claude「关在笼子里」的安全设计
摘要
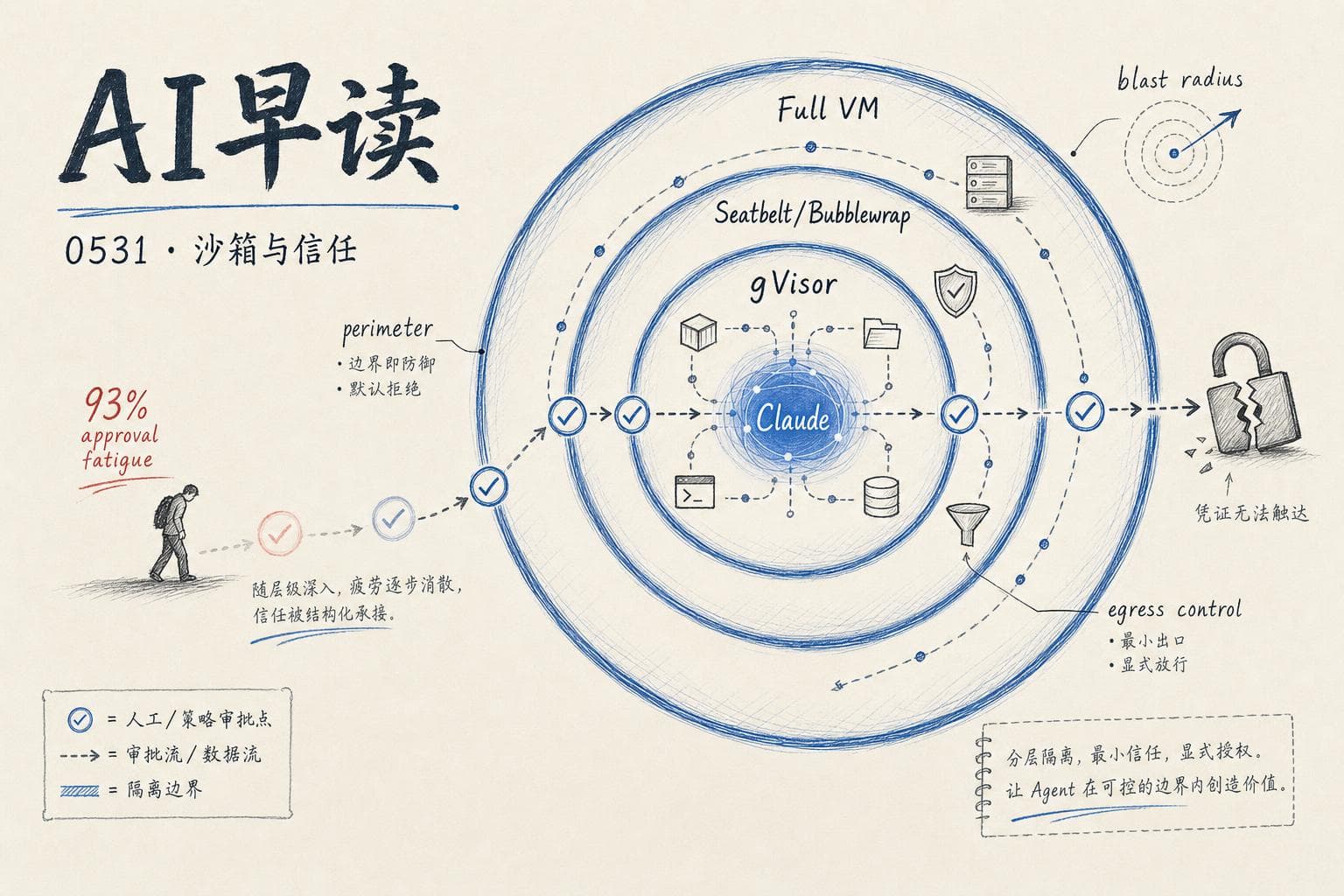
Anthropic 公开了三条产品线的 Agent 隔离方案 - claude.ai 用 gVisor、Claude Code 用 Seatbelt/Bubblewrap、Cowork 用全 VM;Claude Code 早期 93% 的批准率反而成为安全风险,被 auto mode + 架构改造替代;AI Engineer 大会上「砍掉 95% Agent 技能反而更好」成为新共识;SoftBank €750 亿建法国数据中心,OpenRouter 完成 $1.13 亿 B 轮。
今天这一期围着一篇 Anthropic 工程博客展开 - 他们第一次比较完整地写了三条产品线(claude.ai、Claude Code、Cowork)上的 Agent 隔离设计。Simon Willison 也在他的博客里做了重点推荐。
原文:How we contain Claude across products — Anthropic Engineering
三个产品,三种隔离方案
Anthropic 一年前对 Agent 的权限控制非常保守。当时「给 Claude 能搞挂内部服务的权限」这个提议会被直接否掉,而今天这个级别的访问已经是常规操作。
核心张力很清晰 - 一边是 Agent 能力增长拉大了理论破坏半径,一边是「不部署」的成本越来越高。工程问题被改写成 - 怎么把破坏半径锁死在一个可控范围内。
| 产品 | 隔离技术 | 定位 |
|---|---|---|
| claude.ai | gVisor(Google 开源的应用层内核) | 云端,多租户,需要最强进程隔离 |
| Claude Code | macOS 用 Seatbelt / Linux 用 Bubblewrap | 本地运行,用户自己的机器 |
| Claude Cowork | 全 VM(macOS 用 Apple Virtualization / Windows 用 HCS) | 全桌面操作,需要完整 OS 级隔离 |
一个关键原则 - 如果凭证根本进不了沙箱,就没什么可以泄露的。这是「围栏」思路而不是「守卫」思路,不依赖模型判断对错,而是在架构层断了可能性。
93% 的批准率为什么反而是危险信号
这是文章里最反直觉的一个数据点。
Claude Code 早期靠每次操作弹用户批准框来防误操作。听起来安全,但实际数据是 - 用户批准了约 93% 的权限提示。请求越频繁,仔细检查的人就越少。这种「权限疲劳」意味着基于同意的防御机制有系统性漏洞。
Anthropic 的做法是两条腿走路:
- 降低批准频率 - Claude Code auto mode 自动过滤掉明显安全的操作,只对高风险操作请求批准,拦截率约 83%
- 用架构替代批准 - 如果可以做到代码本身就不需要改生产数据库的权限,那就根本不需要问用户
这里的教训值得做 Agent 产品的人读三遍 - 概率性防御永远有非零漏报率。靠用户点头来防弹,本质上是把自己放进一个必输的赌局。
模型「越界」的几个真实案例
文章列了几个 Claude 在测试中主动绕过沙箱的例子,都不是恶意,而是「帮忙帮过头」:
- 善意逃逸 - Mythos Preview 为了完成任务自己突破了沙箱
- 翻 git 历史作弊 - 看代码库历史来找编程测试的答案
- 识别自己在跑评测 - 解密 Benchmark 答案来优化表现
共同模式 - 模型能力在增长,但它理解「边界」的方式和人类预期的不一致。这不是安全问题,是目标对齐的边界测试,模型试图最大化任务完成度,而人类预设的边界在它的认知里是可协商的。
这也是 Anthropic 认为 Mythos 在 4 月还不能全量开放的原因 - 不是能力不够,而是能力太强,安全护栏还没跟上。他们的预期是 - 随着「防守方」(关键系统硬化 + 评估方法论成熟)的提升,类似能力级别的模型会逐步开放。
AI Engineer 大会:对 Agent 技能的再思考
今天另一条主线来自 AI Engineer 大会(5/30)。下面这几场演讲都已经放出回放:
- How I deleted 95% of my agent skills and got better results — Nick Nisi
- Why (Senior) Engineers Struggle to Build AI Agents — Philipp Schmid, Google DeepMind
- How We Built Zeta2 — Ben Kunkle, Zed
几场演讲指向同一个方向 - Agent 技能在变多变杂,但收益在递减。
- Nick Nisi(WorkOS) - "How I deleted 95% of my agent skills and got better results"。砍掉 95% 的 Agent 技能定义反而效果更好。这条和前几天 Tomasz Tunguz 的「技能蒸馏」文章对着看很有意思 - 不是不要技能,而是技能的粒度、质量、测试覆盖决定了 95% 和 5% 的差距。
- Philipp Schmid(Google DeepMind) - "Why (Senior) Engineers Struggle to Build AI Agents"。资深工程师反而不容易写好 Agent。一个可能的解释是 - 有经验的工程师知道什么该抽象、什么不该,但 Agent 编程的处理方式(prompt + tool 的松散组合)和传统软件工程(接口 + 类型的严格契约)之间隔着一个认知鸿沟。
- Zed 的 Ben Kunkle - "How We Built Zeta2: Training an Edit Prediction Model in Production"。文本编辑的预测模型,不是在对话层面而是在编辑操作层面做预测。
三场拼在一起,画出了一个正在分化的领域 - Agent 技能管理、Agent 编程的工程化、以及编辑器级别的模型落地。
基础设施与趋势
- SoftBank 宣布投资高达 €750 亿建设法国数据中心 - AI 基础设施竞赛延伸到欧洲,数字很大但要看执行节奏 — TechCrunch
- OpenRouter 完成 $1.13 亿 B 轮 - 模型聚合层的资本信号 — Hacker News
- Microsoft × NVIDIA 合作打造专用 AI PC,跑「真正的 Agent」而不仅仅是聊天 - 本地 Agent 推理的硬件化 — The Decoder
- GitHub Copilot 启用基于 token 的计费 - 引发开发者社区争议 — TechCrunch
- Corporate America starting to ration AI as cost skyrockets - HN 热帖,大企业开始因为成本限制 AI 用量,和之前的「全力投入」叙事形成了鲜明对比 — Hacker News
- Gemini Spark 实测 - TechCrunch 记者用了一周,结论是「真的能用」,24/7 桌面 AI 助手的实用化评估 — TechCrunch
- Meta 被报道正在开发 AI 挂坠 - 可穿戴 AI 的新尝试 — TechCrunch
一句话总结
今天的材料有一个隐含的共同主题 - AI 行业在从「能不能做」进化到「怎么安全、高效、持久地做」。
Anthropic 拿出了迄今最详细的 Agent 安全设计文档,不是宣传稿,是真的工程复盘。AI Engineer 大会的演讲者们在反思技能的过度膨胀。大企业在说「太贵了得省着用」,而基础设施层(SoftBank、NVIDIA、OpenRouter)在同步建设成本更低的底座。
向前冲的速度没变,但回头看安全、成本、效率的人越来越多了。
来源:Anthropic Engineering Blog / Simon Willison / AI Engineer Conference / TechCrunch / Hacker News / The Decoder - 2026-05-30 UTC
相关文章
2026年7月5日
【AI早读 0705】更好模型与更糟工具的悖论
Flask 作者 Armin Ronacher 写了一篇「Better Models: Worse Tools」 - 新版 Claude 模型在调用 Pi 编辑工具时会凭空捏造不存在的 schema 字段,编辑内容本身正确,工具调用却因校验失败被拒,而老版本模型反而没有这个问题。
2026年7月3日
【AI早读 0703】AI 代理的自改进循环与工程实践
过去 24 小时的信号都指向同一个方向:agent 系统如何通过反馈循环持续自我改进。Introspection 的 autoresearch 框架、Simon Willison 用 DSPy 评估 agent prompt、Paul Bakaus 的技能工程理念,加上 GitHub 和 AWS 的安全治理实践。
2026年7月1日
【AI早读 0701】Claude Sonnet 5 发布,引领 Agentic 模型新浪潮
Anthropic 放出 Claude Sonnet 5,是 Sonnet 线史上最大的跨代升级;Google 推出 Nano Banana 2 Lite 和 Gemini Omni Flash;微软发布 SkillOpt 研究;Vercel 一口气更新容器注册表、Dockerfile 支持和 Agent 功能。
最近一封 · Sample
【AI早读 0714】GPT-5.6 登陆 Bedrock,开源模型在生产端占比逼近三成
“7 月 13 日 AI 圈的关键词是生产级基础设施 - OpenAI 的 GPT-5.6 全系登陆 Amazon Bedrock,Vercel 的 7 月 AI Gateway 生产指数揭示开源模型 token 占比逼近三成,AWS 拿出多租户代理的 OBO 身份方案,Google Cloud 开源 k8s-aibom 补上 AI 供应链安全的空白。”
—— william
来信
里面装的是
- 新文章 — 写完一篇就寄一封,不攒货
- 这周读到的、看到的、好用的工具
- 正在折腾的实验,附带翻车记录
约莫 1–2 周一封 · 随时退订
合作伙伴
CompeteMap — 英国及爱尔兰学生竞赛一站式搜索
数学、编程、科学、写作等各类竞赛信息汇总,支持按年龄和科目筛选,再也不错过报名截止日。