【AI早读 0516】LLM架构新进展与AI学习边界思考
摘要
今天聚焦 LLM 架构、预训练稳定性和 AI 学习边界:Sebastian Raschka 梳理长上下文效率相关的新架构,Dwarkesh Patel 总结打破因果性与引入偏置如何导致训练失败,同时讨论强化学习与人类学习之间不能被忽视的差异。
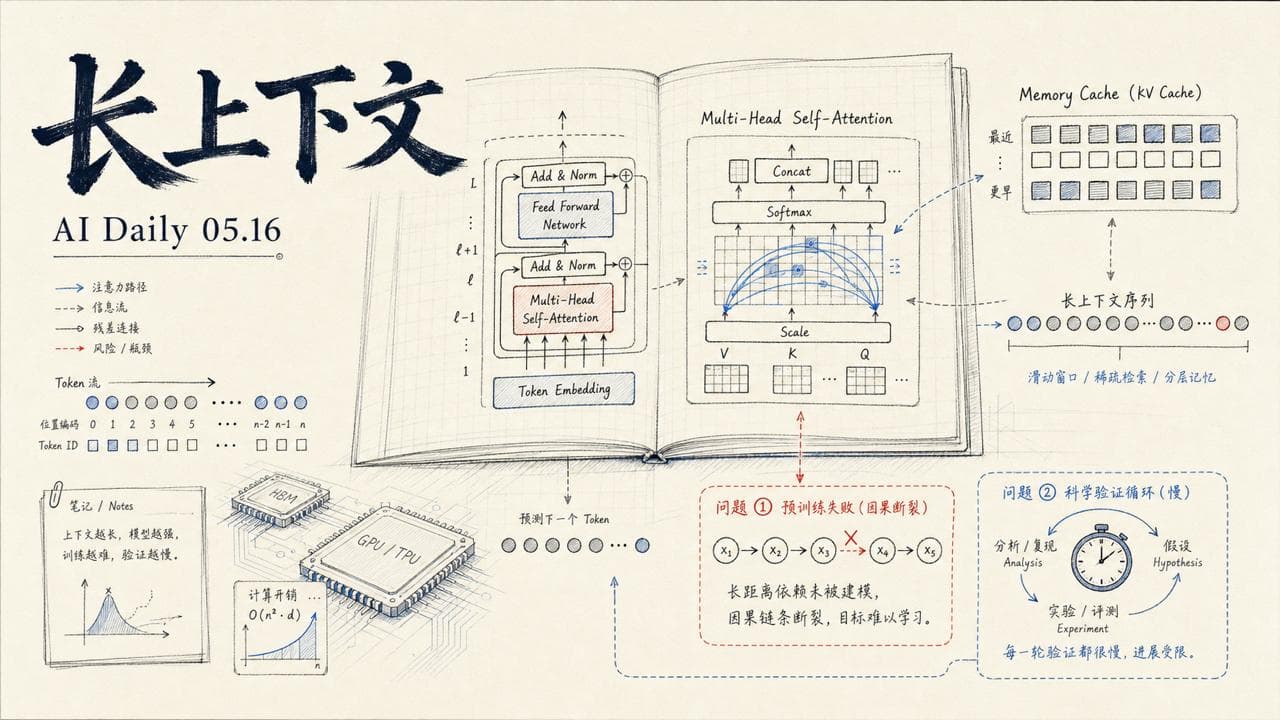
Sebastian Raschka 详解 LLM 架构最新进展
Sebastian Raschka 在休假回来后发了一篇长文,梳理近期开源 LLM 在架构层面的关键变化。核心主线是长上下文效率。
链接:Recent Developments in LLM Architectures
随着 reasoning 模型和 agent 工作流保留了更多 token,KV-cache 大小、内存带宽和 attention 计算开销快速成为主要瓶颈。Raschka 重点分析了几个新架构:
- Gemma 4 的 KV sharing 和 per-layer embeddings
- Laguna XS.2 的 layer-wise attention budgeting
- ZAYA1-8B 的 compressed convolutional attention
- DeepSeek V4 的 mHC 和 compressed attention
这些改动在架构图上看起来都是小调整,但实际设计相当精密。值得关注的是 DeepSeek V4 虽然还未正式发布,但架构细节已经在社区扩散。
Dwarkesh Patel:Pretraining 失败的真实原因
Dwarkesh Patel 和一位业内人士聊了聊训练跑飞的原因,整理了一份笔记。核心概念是两个罪魁祸首:打破因果性和引入偏置。
链接:Notes on pretraining parallelisms and failed training runs
他谈到的两个有趣的技术细节:
- Expert Choice routing(只在训练中使用)- 这种方法可以保证每个 expert 分配到大致相同数量的 token,但它打破了因果性:token n 被分配到哪个 expert 可能取决于 token n+k 的 router 结果。有传言说这解释了为什么 Llama 4 表现不及预期
- Token dropping - experts 忽略批次中匹配较弱的 token 以节省 padding。这同样打破因果性,据称 Gemini 2 Pro 遇到过这个问题
他还做了一个 pretraining flashcards 页面 帮助记忆这些概念。
Addy Osmani:不要把学习外包给 AI
一篇值得反思的短文。Addy Osmani 观察到一种普遍的默认模式:粘贴错误信息 - 模型给修复 - 症状消失 - 你交付了。
链接:Don't Outsource the Learning在这个过程中,问题解决的 messy struggle 完全不存在了。
他之前写过 cognitive surrender(认知投降)的概念 - AI review 的结果静默替换了你自己的判断。这篇文章是同一个循环的单人版本。数千次这样的小交互累积下来,没有 AI 辅助时你实际能造的东西每星期都弱一点。
不是反 AI 工具 - 他每天也用。但默认的使用方式优化的是交付速度,而不是理解深度。
Dwarkesh Patel:RLVR 可能对科学特别不擅长
另一个来自 Dwarkesh 的思考。有些人认为 AI 会特别擅长科学突破,理由是科学是可验证的,而 AI 在拥有紧密验证循环的领域(编程、数学)里通过 RL 做到了顶尖水平。
链接:RLVR might be disproportionately bad at science
但他指出人类科学史说明验证循环的时间尺度可以是数十年甚至数百年,而且实验极少能彻底排除替代解释。公元前 2 世纪的古希腊人就因为无法测量恒星视差而否定了 Aristarchus 的日心说 - 第一次成功测量恒星视差是 1838 年。
来源:VerySmallWoods Research Feed - 2026-05-16 UTC
相关文章
2026年6月19日
【AI早读0619】GLM-5.2登顶开源,智能体安全框架密集发布
GLM-5.2 以 753B MoE、百万 token 上下文和 IndexShare 稀疏注意力机制登顶开放权重模型;Google DeepMind 发布 AI Control 路线图,Amazon Bedrock AgentCore 正式 GA,智能体安全与运行基础设施同步加速。
2026年6月15日
【AI早读 0615】安全对齐与WASM生态
Google DeepMind 解释为什么简单过滤 SFT 数据难以消除安全相关行为,关键可能在教师模型回答的行为迁移;Pyodide 开始支持把 WASM wheels 直接发布到 PyPI;GPU 时间分片则为 Kubernetes 上并发运行多个 LLM Agent 提供工程路径。
2025年1月26日
DeepSeek-R1: 通过纯强化学习打造的推理型大模型
探索DeepSeek团队在大语言模型推理能力提升方面的创新方案,包括纯强化学习的R1-Zero和结合冷启动的R1模型。
最近一封 · Sample
【AI早读 0620】AI Agent 重塑软件生命周期
“Google 的新软件生命周期白皮书把 Agent 定义为“模型加 harness”,强调 Context Engineering、验证和渐进式披露;多篇实践进一步展示 Agent 如何从写代码延伸到部署、数据分析、信息检索和云平台运维。”
—— william
来信
里面装的是
- 新文章 — 写完一篇就寄一封,不攒货
- 这周读到的、看到的、好用的工具
- 正在折腾的实验,附带翻车记录
约莫 1–2 周一封 · 随时退订
合作伙伴
CompeteMap — 英国及爱尔兰学生竞赛一站式搜索
数学、编程、科学、写作等各类竞赛信息汇总,支持按年龄和科目筛选,再也不错过报名截止日。