【AI早读 0519】Agent评估到部署,以及长时任务智能体的稳定性
摘要
今天聚焦 Agent 从评估到部署 - IBM 跨场景排行榜、OpenAI×Dell 把 Codex 推进企业本地环境、Anthropic 谈长时任务稳定性,以及一份系统的 Agent 评估指南。
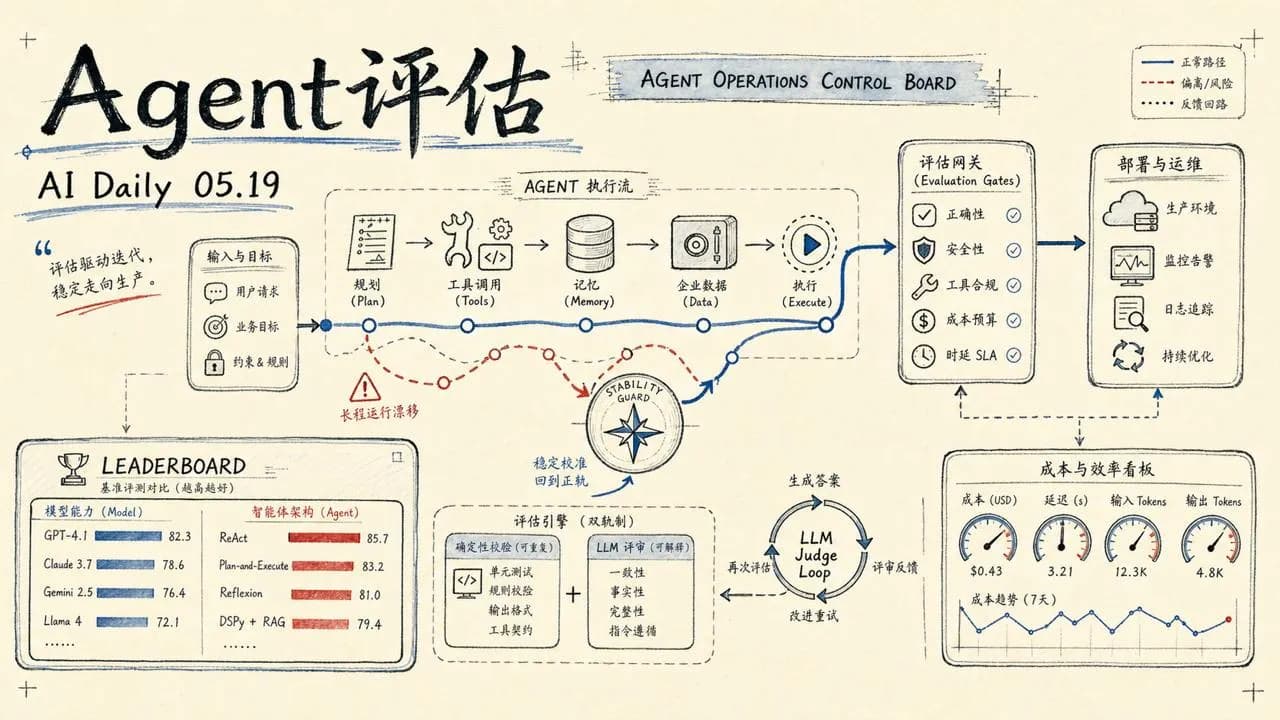
今天的内容集中在 Agent 系统从评估到部署的各个层面。IBM 开放了一个跨场景的 Agent 排行榜,把模型和 Agent 架构拆开比;OpenAI 跟 Dell 联手把 Codex 推入企业本地环境;Anthropic 的人出来聊长时间 Agent 的稳定性问题;Cameron Wolfe 写了一篇非常系统的 Agent 评估指南 - 两篇 AWS 博客分别覆盖了 Bedrock AgentCore 的自定义评估和 Nova 2 的内容审核。
OpenAI × Dell:Codex 进入混合云与本地部署
OpenAI 宣布与 Dell 合作,将 Codex 带入企业的混合云和本地(on-premises)环境。Codex 目前每周有超过 400 万开发者使用,使用场景已从代码审查、测试覆盖扩展到事故响应和跨仓库推理。更值得留意的是,Codex 驱动 Agent 已经开始出现在业务系统里 - 收集上下文、准备报告、路由产品反馈、线索筛选、写跟进邮件、协调跨系统工作流 - 这些已经不是实验阶段。
这次合作的关键是 Dell AI Data Platform 和 Dell AI Factory。Codex 会接入 Dell 已有的数据平台,让 Agent 离企业内部代码库、文档、业务系统和工作流知识更近。Dell 的基础设施配上 OpenAI 的 Agent 工具,企业其实拿到了一条「数据不动、Agent 过来」的路径。具体来说,Dell AI Factory 与 ChatGPT Enterprise 和 API 方案之间的配合也已被列入探索范围。
IBM 开放 Agent 排行榜:把架构和模型拆开看
IBM Research 在 Hugging Face 上发布了 Open Agent Leaderboard。它的设计理念很直接:Agent 跑得好不好不只是模型的事 - 工具怎么设计、规划怎么执行、记忆怎么组织、出错怎么恢复,每一项都影响结果。同一个模型配上不同的 Agent 系统,得分和成本可以差很多。
排行榜覆盖六个场景:SWE-Bench Verified(代码修复)、BrowseComp+(开放研究)、AppWorld(跨应用个人任务)、tau2-Bench Airline & Retail(客服)、tau2-Bench Telecom(技术支持)。每个场景都有不同的工具、规则和约束 - 测的不是系统在单一任务上的优化,而是它在陌生环境下的泛化能力。
目前的结果有几个有趣的发现。通用 Agent 在多个场景上已经能与专门优化的系统匹敌甚至超越。失败的行为差异也很大 - 有的快速失败、成本低,有的烧长链后才放弃。实验中失败的运行比成功的贵 20–54%。这对生产环境中账单的影响比人们意识到的要大。
排行榜同时报告质量和成本,每一行都是完整的 Agent 系统(特定 Agent + 特定模型)。Exgentic 框架和论文全部开源。
Anthropic 谈长时间 Agent 的稳定性
AI Engineer 频道发布了一场新对谈,Anthropic 的 Ash Prabaker 和 Andrew Wilson 讨论了构建「能跑数小时而不丢失上下文」的 Agent。这个话题的实用性很高 - 短周期 Agent(单轮问答、一次性代码生成)已经被大量实践覆盖,但长时间运行的 Agent 面临的核心难题是上下文退化、错误累积和规划漂移。
虽然没有详细摘要,但这个方向本身就是一个明确的信号:行业对 Agent 的注意力正在从「能不能做」转向「能稳定做多久」。对于任何正在把 Agent 推向生产的人来说,这个话题比新模型发布更贴近日常痛点。
Agent 评估实战指南
Cameron Wolfe 的《Agent Evaluation: A Detailed Guide》是一篇很系统的综述。他从 Agent 的基本定义讲起 - 最简定义就是「在循环中自主使用工具的 LLM」 - 然后逐步展开到评估框架的设计。
文章的核心观点值得重复:Agent 和传统 LLM 的评估方式完全不同。过去我们拿静态问答测模型,现在的 Agent 系统有长时间跨度、与环境交互、有自主决策。要准确衡量一个 Agent 系统的能力,评估环境必须足够逼真、能覆盖 Agent 在实践中会遇到的各种情况。
关于工具调用的内部机制,文章用 Qwen3 的 XML 标签实现做例讲解(<tool_call> / </tool_call> 作为特殊 token),解释了推理时如何拦截输出、解析请求、调用工具、拼接结果、再继续生成 - 整个循环实现并不神秘。
链接:Agent Evaluation: A Detailed Guide
AWS 双管齐下:AgentCore 自定义评估 + Nova 2 内容审核
AWS 在同一天发了两篇值得读的博客。
第一篇讲 Bedrock AgentCore 的自定义代码评估器。对于金融和专业领域,很多检查不是语言层面的 - 股价波动范围、经纪人身份验证、JSON schema 校验、PII 过滤 - 这些需要确定性的代码而非 LLM-as-a-Judge。AgentCore 允许用 Lambda 函数作为评估引擎做正则校验、结构化验证、外部数据查询。同一个评估器可以同时用于开发工作流的门禁和线上流量的评分。
第二篇讲 Amazon Nova 2 Lite 的内容审核。如果用 MLCommons AILuminate 12 类风险分类法做 prompt 模板,Nova 2 的结构化提示在多个基准数据集上的表现与其他基础模型有可比性 - 且不需要标注数据和微调,改策略就是改 prompt。
链接:Build custom code-based evaluators in Amazon Bedrock AgentCore
链接:Prompting Amazon Nova 2 for content moderation
其他值得关注的条目
- Anthropic 收购了 Stainless(API SDK 生成工具)。这意味着 Anthropic 在基础设施工具链上又加了一块拼图。链接:Anthropic acquires Stainless
- Hippocratic AI 与 Modular 合作做医疗场景的实时推理,用 Modular 的引擎驱动病人对话。链接:Hippocratic AI partners with Modular
- Cloudflare Project Glasswing 分享了 Mythos 竞赛的收获 - 用前沿模型做网络安全防御的实验。链接:Project Glasswing: what Mythos showed us
- NVIDIA Cosmos Predict 2.5 的 LoRA/DoRA 微调指南已发布,面向机器人视频生成场景。链接:Fine-Tuning NVIDIA Cosmos Predict 2.5 with LoRA/DoRA
- PaddleOCR 3.5 发布了 Transformers 后端版本,OCR 和文档解析在 Hugging Face 生态中更易集成了。链接:PaddleOCR 3.5: Running OCR and Document Parsing Tasks with a Transformers Backend
来源:VerySmallWoods Research Feed - 2026-05-19 UTC
相关文章
2026年6月12日
【AI早读0612】OpenAI收购Ona为Codex构建持久化Agent执行环境
今天的主线是 AI Agent 正在走向“生产级”:OpenAI 收购 Ona,给 Codex 补上持久化云端执行 —— 电脑离线后 Agent 仍能在企业自有云里接着跑。Google Cloud 用 TEE 推出 Confidential AI 保护推理数据;Anthropic 发布企业订阅 Claude Corps 并联合 DXC 进入受监管行业;AWS 开源 Agent-EvalKit 系统化评估 Agent 全执行链路;再加 DeepMind“模型察觉被评估反而表现更差”的研究与多 Agent 安全投资。
2026年6月10日
【AI早读 0610】Claude Fable 5 全平台上线,Gemma 4 12B 开源本地多模态
6 月 9 号是今年最密集的 AI 发布日之一:Anthropic 正式放出前沿模型 Mythos 5 与消费版 Fable 5,强项在超长上下文 agentic coding,但定价翻倍、普通用户感知有限,并同步上架 Google Cloud。Google DeepMind 开源 Gemma 4 12B 无编码器多模态模型,16GB 显存即可本地跑。OpenAI 连发 Codex 企业落地案例,AWS 放出两篇 agent 实践,Cloudflare 分享前沿模型攻击的防御架构。
2026年5月28日
【AI早读 0528】智能体评测与进化
ITBench-AA 显示所有前沿模型在企业级 IT 智能体任务上均低于 50%;OpenAI 与 Thrive 的 Tax AI 案例展示了 Codex 如何把生产纠错变成自改进循环;Warp 用 GPT-5.5 推动开源智能体开发;Alignment Forum 讨论评测博弈与 AI 研发自动化。
最近一封 · Sample
【AI早读 0621】透明度与人才流动:Google 给扩散模型做解剖,AlphaFold 之父投奔 Anthropic
“Google DeepMind 对 DiffusionGemma 展开透明度审计,发现扩散语言模型的中间变量仍可解释,但非时序推理让算法透明度更具挑战;AlphaFold 创造者 John Jumper 离开 DeepMind 加入 Anthropic;Codex 则新增从一次操作演示中学习并重复执行工作流的能力。”
—— william
来信
里面装的是
- 新文章 — 写完一篇就寄一封,不攒货
- 这周读到的、看到的、好用的工具
- 正在折腾的实验,附带翻车记录
约莫 1–2 周一封 · 随时退订
合作伙伴
CompeteMap — 英国及爱尔兰学生竞赛一站式搜索
数学、编程、科学、写作等各类竞赛信息汇总,支持按年龄和科目筛选,再也不错过报名截止日。